
¡Los Modelos de Lenguaje (LLMs) son increíbles, pero tienen un gran problema: tienen memoria a corto plazo y no conocen tus datos privados!
Si le preguntás a ChatGPT o a Llama 3 sobre los reportes financieros de tu empresa del mes pasado, la política interna de reembolsos o el catálogo específico de tu e-commerce, lo más probable es que pase una de dos cosas: o te dice que no tiene esa información, o peor aún, alucina e inventa una respuesta que suena completamente convincente.
Acá es donde entra RAG (Retrieval-Augmented Generation), la tecnología que está revolucionando la forma en que las empresas usan la Inteligencia Artificial.
En esta guía te vamos a explicar, sin tecnicismos innecesarios, qué es RAG, cómo funciona y por qué se convirtió en la arquitectura obligatoria para cualquier desarrollador o empresa que quiera implementar IA real.
¿Qué es RAG (Generación Aumentada por Recuperación)?
RAG son las siglas de Retrieval-Augmented Generation (Generación Aumentada por Recuperación). Es una técnica de arquitectura de software que conecta un modelo de IA con una fuente de información externa y dinámica (como una base de datos, un Notion, PDFs o un CRM).
Para entenderlo de forma simple, imaginate este escenario:
- Un LLM sin RAG es como un estudiante rindiendo un examen de memoria. Sabe mucho en general, pero si le preguntás un dato muy específico o reciente que no estudió, va a fallar o a adivinar.
- Un LLM con RAG es ese mismo estudiante rindiendo el examen a libro abierto. Antes de responder, busca en el libro la página exacta que contiene la información, la lee, y te da una respuesta redactada a la perfección basada en lo que acaba de encontrar.
En resumen: RAG no entrena de nuevo a la IA. Lo que hace es darle el «contexto» correcto en el momento exacto para que responda con la verdad.
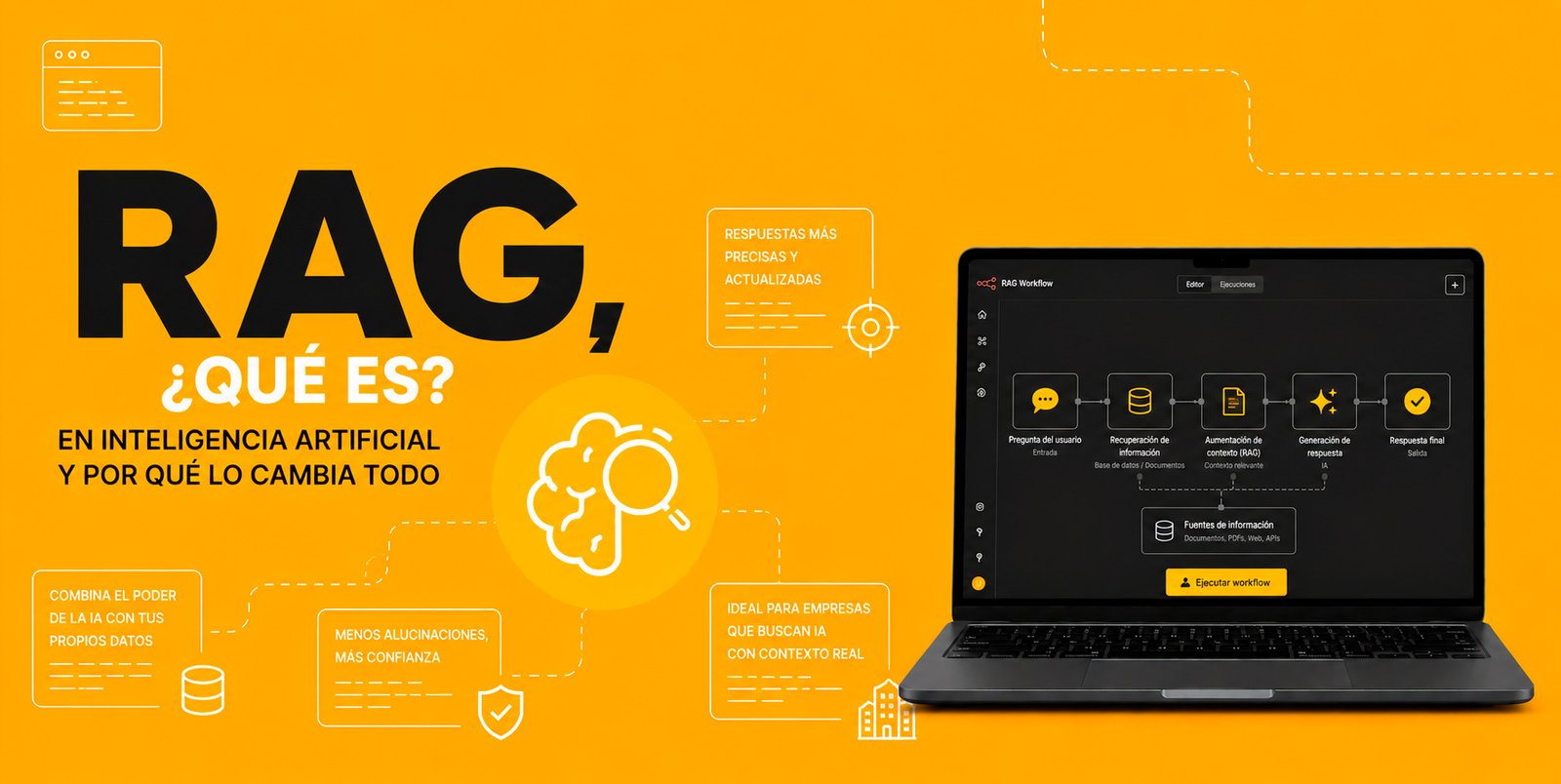
¿Cómo funciona la arquitectura RAG? (Paso a Paso)
Aunque suena complejo, el flujo de trabajo de un sistema RAG se divide en tres etapas muy claras:
[Tu Pregunta] ➔ [Búsqueda en Base de Datos Vectorial] ➔ [Pregunta + Contexto] ➔ [LLM] ➔ [Respuesta Precisa]
1. La Ingesta de Datos (Embedding)
Primero, tus documentos de texto (manuales, contratos, logs) se rompen en fragmentos chicos (chunks). Esos fragmentos se transforman en números (vectores) mediante un proceso llamado embedding y se guardan en una base de datos vectorial (como Pinecone, Chroma o Supabase). Esto permite que la IA entienda el «significado» semántico de tus textos.
2. La Recuperación (Retrieval)
Cuando un usuario hace una pregunta, el sistema busca en la base de datos vectorial cuáles son los fragmentos de tus documentos que más se relacionan semánticamente con la consulta.
3. La Generación (Augmentation)
El sistema toma la pregunta original del usuario, le pega los fragmentos de información real que encontró en el paso anterior, y le manda todo empaquetado al LLM. El modelo de lenguaje lee la información y redacta una respuesta natural, precisa y libre de alucinaciones.
RAG vs. Fine-Tuning: ¿Cuál es mejor?
Cuando una empresa quiere que la IA aprenda de sus datos, suele dudar entre hacer Fine-Tuning (Ajuste Fino) o implementar RAG. Esta tabla comparativa te va a aclarar el panorama al instante:
| Característica | RAG (Retrieval-Augmented) | Fine-Tuning (Ajuste Fino) |
| Costo de implementación | Bajo / Moderado | Alto (requiere mucho poder de cómputo) |
| Actualización de datos | Instantánea (solo actualizas la base de datos) | Lenta (hay que volver a entrenar el modelo) |
| Precisión/Alucinaciones | Muy bajas (se basa en fuentes reales) | Moderadas (puede seguir alucinando) |
| Trazabilidad | Alta (te puede decir de qué PDF sacó el dato) | Nula (el conocimiento queda diluido en la red neuronal) |
| Ideal para… | Consultar datos internos, manuales y conocimiento vivo. | Cambiar el tono de la IA o enseñarle un lenguaje muy específico. |
Las Ventajas de usar RAG en tus proyectos de IA
Si estás pensando en desarrollar un chatbot o una automatización para tu negocio, implementar esta arquitectura te da tres beneficios clave:
- Adiós a las alucinaciones: Al limitar las respuestas de la IA a la información provista en el contexto, reducís casi a cero la posibilidad de que el sistema invente datos corporativos o comerciales.
- Seguridad y Privacidad: Podés controlar qué información recupera el sistema según el rol del usuario que pregunta, protegiendo datos sensibles.
- Economía de recursos: Mantener una base de datos documental es infinitamente más barato que re-entrenar modelos de lenguaje gigantescos cada vez que cambia un precio o una política.
Herramientas clave para armar tu primer stack RAG
Si querés empezar a construir un sistema RAG hoy mismo, estas son las herramientas líderes en el mercado que tenés que conocer:
- Frameworks de Orquestación: LangChain y LlamaIndex son los reyes indiscutidos para conectar los LLMs con tus fuentes de datos.
- Bases de Datos Vectoriales: Pinecone, Weaviate, ChromaDB, o incluso extensiones como pgvector para PostgreSQL.
- Automatización Low-Code: Herramientas como n8n (mediante sus nodos avanzados de IA avanzados) te permiten montar un flujo RAG completo visualmente y en cuestión de minutos, conectando gatillos de Webhooks con bases de datos vectoriales.
El futuro de la IA corporativa es «Aumentado»
El verdadero valor de la Inteligencia Artificial no está en lo que sabe de internet en general, sino en cómo puede aplicar esa inteligencia a tus datos particulares. RAG es el puente que une la potencia cognitiva de los grandes modelos de lenguaje con la realidad de tu negocio.
¿Estás listo para armar tu primer sistema de IA sin alucinaciones? En los próximos artículos del blog vamos a ensuciarnos las manos con tutoriales prácticos de código y automatizaciones para implementar RAG desde cero. ¡Dejanos en los comentarios qué herramienta te gustaría que analicemos primero!